A close look at this underground workforce
Understanding the data supply chain behind training generative AI is essential to show who profits from this precarious billion-dollar industry.
Este artigo sobre a metodologia da reportagem também foi publicado em português. Leia-o aqui.
“Ghosts.” “Phantoms.” These are words commonly used to portray the workers training artificial intelligence systems. Despite their crucial role in supporting generative AI, the industry hides their existence. The task of training data systems is far less glamorous than writing code in modern Silicon Valley offices.
Laborers, usually hailing from the Global South, are paid pennies to perform tasks that are integral to the development of new AI systems, particularly generative AI, which requires an ever-increasing volume of data.
To learn from patterns in the data, generative AI systems require a prodigious number of photographs, videos, audio files, transcripts, translations, and data annotations, and it takes an army of workers to comb through this material and teach the interface what is and is not acceptable.

As a nonprofit journalism organization, we depend on your support to fund more than 170 reporting projects every year on critical global and local issues. Donate any amount today to become a Pulitzer Center Champion and receive exclusive benefits!
Major tech companies have found an efficient method to minimize the cost of this data classification: subcontract poorly compensated workers to perform these tasks through digital platforms. People are paid for "microtasks"—repetitive and fragmented work that develops databases feeding AI systems worldwide.
This work is fragmented and isolated. People rarely know which system they are training—and often, they don’t even know the company they’re working for. Due to this intentional lack of transparency, workers may unknowingly train systems used for surveillance and repression, as my colleague Niamh McIntyre revealed, or fact-check for a large social network like Facebook, as I have shown. To draw a parallel with the Industrial Revolution, it is as if the worker is simply tightening a bolt repeatedly, not knowing the bolt would later be used to build a bomb.
To report on AI contractors, you must know that the chain of command is extremely opaque and secretive. Workers sign very strict NDAs and often can’t even organize into groups or talk about their experiences on the platform. Companies have no interest in shedding light on their hidden processes. In this way, they're able to control payments and work processes and prevent workers from organizing themselves. That’s where journalism comes in—to search for the human impact.
Understanding the production chain
The flow of training data used in AI models is a production chain: The workers are at one end, the intermediary companies who hire them on a per-task basis comprise the middle, and at the other end sit the tech companies, that is, the developers of AI systems who require the data.

To begin investigating, you must first understand the players in the chain: Who are the intermediary data companies, and which tech companies do they have contracts with? You can find this information in publications from specialized tech and AI outlets, as well as through company disclosures and financial statements. This will allow you to understand who the big players in the data market are.
But how do you discover information about the work itself—that is, which tasks are tech companies hiring for? On platform websites, the only public information available about tasks are the job postings themselves. However, nicknames and cryptic codes occlude a project’s aim and contractor. Only generic descriptions such as “find fake content online,” “contribute to a safer internet,” or “improve identification technologies” are offered.
Identifying the other end of the chain, the workers, is also not a simple task. The good news is that there are already many researchers in this field and initiatives that can help with references and contacts.
I received valuable guidance from Brazilian psychologist and researcher Matheus Viana Braz, who has authored several studies on microwork. Braz aided me in finding dozens of online support groups in which workers were already organizing. There are also several initiatives worldwide, like Data Workers Inquiry, AI Kenya, and Fairwork, that sponsor consistent research and advocacy efforts with data workers.
Although it is formally prohibited to talk about tasks outside the platforms, workers organize themselves in groups and forums on social networks. Studies show that it is in these spaces that workers can support each other, share tips, and even improve the quality of the work performed, as most projects lack adequate training.
Due to strict terms of use and workers’ extreme need to avoid being banned, most are not interested in talking to journalists. One reason is the fear of popularizing the work—which could make it more competitive, and, as a result, drive down the pay. The other reason is the obvious fear of leaking any information and, thus, being punished for breaking the company’s confidentiality agreement.

To identify the beneficiaries of these workers and their working conditions, it became necessary to build a database from scratch and map the entire chain.
My database started with the only public information available: the job postings for the projects. I asked for help from Federico Acosta Rainis, data specialist at the Pulitzer Center, to scrape public information from all the job openings posted by the major data work platforms: the project’s name, country, task, and payment. I began organizing this information and collecting dozens of remote job openings.
Each job opening represents an isolated “task,” hidden by “projects” that give the intermediary the ability to hide each end of the chain from one another.
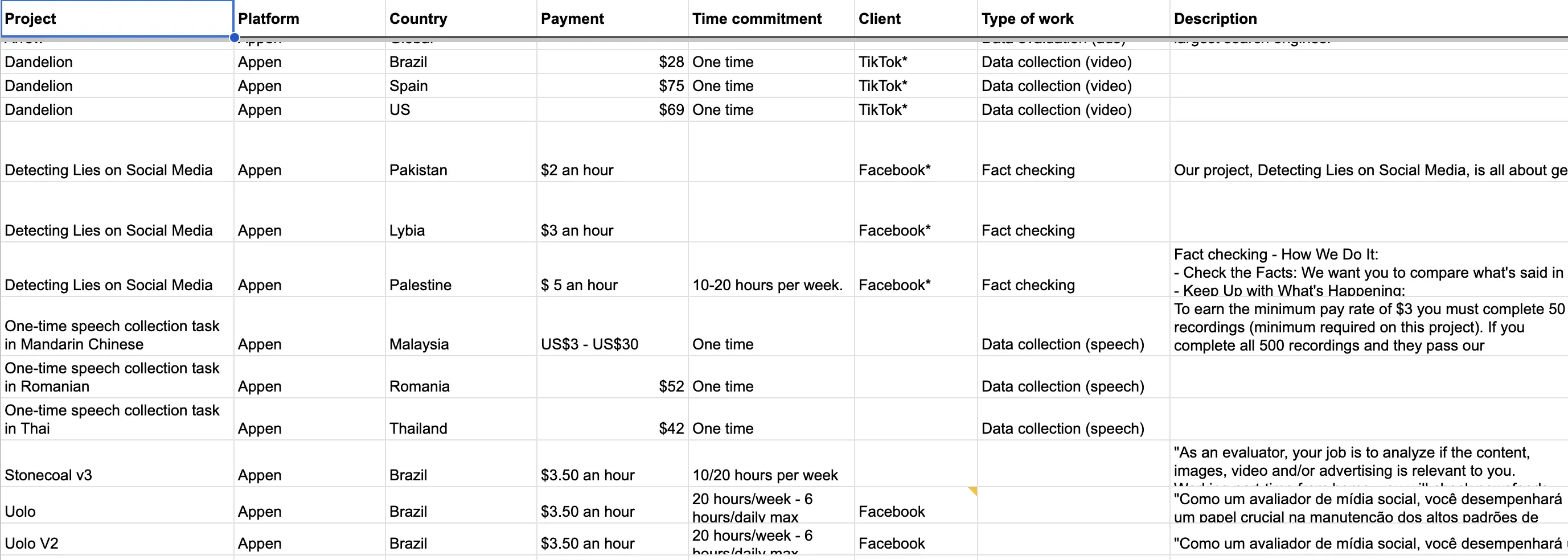
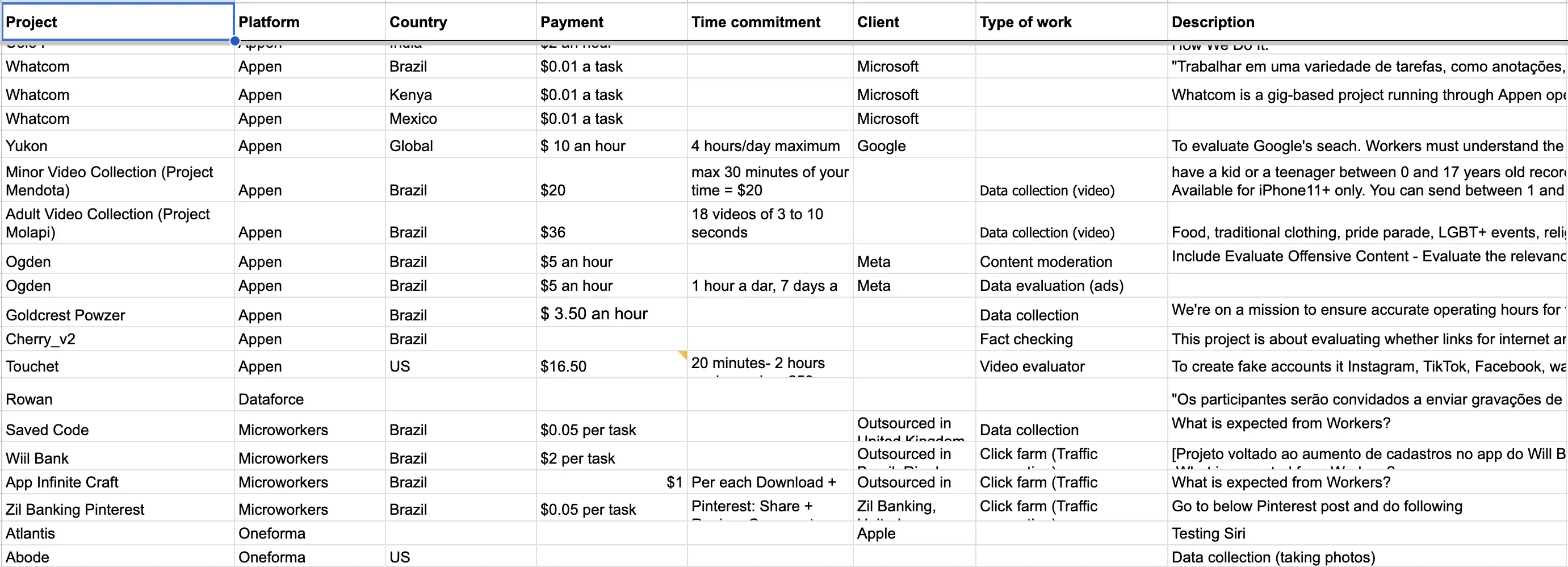
To identify the clients for each project, one effective method I found was to look directly at the tasks performed by the workers. My partner Sofia Schurig and I gained entry to dozens of workers’ groups on WhatsApp, Telegram, and Facebook. We introduced ourselves as journalists, but initially, no one wanted to give us interviews. We tried sending out a survey with questions, but the response rate was very low.
Still, as no one banned our presence in those spaces, we started to follow the conversations, problems, and routines of the workers. We gradually became familiar with the project names and came to understand what they entailed.

The Uolo project by Appen, for example, is so popular that there are online support groups exclusively dedicated to it. The project’s goal is to train an AI system to fact-check information. But what is the information? And who is it for?
In the groups, I noticed the challenges workers complained about, notably having to determine whether a given post was true or false in just a few minutes. To give a precise figure, workers had to check at least 40 pieces of content in one hour—an average of 1 minute and 41 seconds for each post. Looking at the comments and screenshots posted by the workers, I was able to deduce that the posts and ads were coming from Instagram and Facebook.
I knew that Meta was a client of Appen through news reports, but I did not know exactly what data workers did for the tech giant until I saw screenshots of tasks, training docs, and URLs from Facebook’s internal system in the support groups.

Neither Appen nor Meta would confirm the existence of a contract between the two entities when asked. How then could I verify if the ads and tasks were authentic? I started to cross-check screenshots of ads that workers had shared, looking to match them with Meta's ad library. Ads identical to those that had circulated in the workers' internal system were present.
When I realized that workers were fact-checking sensitive information, such as posts about the catastrophic floods that beset the south of Brazil in May 2024, I arrived at my first story: "Subterranean Moderators: Meta Trains Artificial Intelligence in Brazil Paying Less Than a Dollar for Fact-Checking on Floods, Violence, and Politics."
Joining the groups also revealed problems workers faced on the job: insecurity, lack of training, technical issues, and language barriers. Workers also encountered numerous cases of non-payment or received payments that were lower than expected. Over time, I began to understand the daily life of the workers: what hours they worked, what they thought of the job, their dreams and struggles. There were people in the groups who only worked at night. Others were willing to help newcomers. I wanted to understand how the work routine functioned and what mechanisms of control the companies had over these people.
We analyzed months of messages to uncover stories about workers’ routines and published their testimony anonymously to protect their privacy. The second story of the series emerged from this research: "The Platform Proletariat: How the Artificial Intelligence Industry Profits From an Unprotected Digital Working Class in Brazil."
Having developed numerous contacts within the online support groups, I soon began to receive training materials, as well as terms of use and NDAs. Getting these documents was crucial for understanding the rules, training, and preparation used to onboard new workers. However, we had to be mindful that workers could face legal or security risks or dismissal. We were cautious in our communications—instead of asking for confidential documents, we left the door open for people to share what they thought might be relevant in our conversations.
It worked.
One of the contracts, for instance, was particularly harsh regarding internal leaks of information. The document also asked workers to waive any right to be able to complain about exposure to explicit content.


Most of the confidential documents we obtained contain serialized watermarks that could risk a source’s anonymity. For this reason, we chose not to publish them. Still, as it was in the public interest to reveal what they said, we released a third story in our series: “Moderators Received 7 Cents per Task to Comb Through Violence, Pornography, and Extreme Content on X.” The article was based on those documents we had received along with anonymous worker testimonies.
There's still much to investigate
From the start, one of my goals has been to shed light on the major clients of online content classification. That’s why I found it crucial to trace the chain of command from one end to the other. The answer to my question quickly became clear: big tech.
Data training is more involved than the derisive label of “microtasks” would suggest. These workers are part of a multibillion-dollar industry, and they deserve to be acknowledged and adequately compensated for their labor. Moreover, it's important to emphasize that work conditions directly affect the quality of the data produced–and, consequently, the outputs generated by AI systems.
A fact-checking system trained poorly will produce poor results on a massive scale, which is hardly cost effective in the long term. When talking about AI accountability, we should think about the entire process: from how data is produced and how systems are trained to the potential risks and biases facing workers. The workers at the forefront must be part of this conversation.
Regardless, many questions remain unanswered. Looking at the tasks, it’s possible to grasp certain trends in the AI industry. Some projects, for instance, pay workers for pictures of children. Yes, pictures of children. Others pay for photos of ID cards. Why does the AI industry need a colossal number of ID cards? And how will the privacy of this vast amount of data be handled?
Another point worth mentioning is that some major tech firms, such as Kwai and TikTok, are embedding within their platforms the ability to hire online content moderators to train AI. A story published in Brazil showed that children and teens are "addicted" to this kind of task, which pays pennies and keeps them glued to the platforms for hours.
Although the issue of human labor is, in my view, one of the most urgent in terms of AI, it is still ignored in most regulatory initiatives. In Brazil, despite the Ministry of Labor and Employment’s creation of a working group to discuss data work, the topic wasn't even included in the AI regulation approved by the Senate last November.
This hands-off attitude assumes that AI appears magically or simply through machines themselves without human support, an idea that, as I’ve tried to show in my reporting, isn’t true. Many humans are feeding this machine. The industry wants to hide them–but one of journalism's roles in AI accountability is to show that they exist.