Recurso Jornalístico
 Fevereiro 4, 2025
Fevereiro 4, 2025
Como investigamos o trabalho humano por trás da IA
País:


Esta investigação segue uma longa cadeia de trabalhadores subcontratados e precários.
Compreender a cadeia de fornecimento de dados para treinar IA generativa é essencial para mostrar quem lucra com esta indústria precária de milhões de dólares.
This methodology piece was also published in English. Read it here.
"Fantasmas." "Escondidos". Estas são palavras habitualmente utilizadas para descrever os trabalhadores que treinam os sistemas de inteligência artificial. Apesar do seu papel crucial no desenvolvimento da IA generativa, a indústria esconde a sua existência. A tarefa de treinar sistemas de dados é muito menos glamourosa do que escrever código nos escritórios modernos do Vale do Silício.
Os trabalhadores, geralmente oriundos do Sul Global, recebem centavos para realizar tarefas que são essenciais para o desenvolvimento de novos sistemas de inteligência artificial, em especial a IA generativa, que exige um volume de dados cada vez maior.
Para aprender a partir de padrões nos dados, os sistemas de IA generativa requerem um número colossal de dados, fotografias, vídeos, áudios, transcrições, traduções e classificações, e é necessário um exército de trabalhadores para preparar esse material e ensinar a máquina a trabalhar com os dados.

Como uma organização jornalística sem fins lucrativos, dependemos de seu apoio para financiar o jornalismo que cobre assuntos marginalizados em todo o mundo. Doe qualquer quantia hoje para se tornar um Campeão Pulitzer Center e receba benefícios exclusivos!
As grandes empresas de tecnologia encontraram um método eficiente para minimizar o custo desta classificação de dados: subcontratar trabalhadores mal remunerados para realizar estas tarefas através de plataformas digitais. As pessoas são pagas por "microtarefas" — trabalho repetitivo e fragmentado que para criar as bases de dados que alimentam sistemas de IA em todo o mundo.
Este trabalho é feito de forma isolada. As pessoas raramente sabem que sistema estão treinando — e, muitas vezes, sequer sabem para que empresa estão trabalhando.
Por causa dessa falta de transparência, os trabalhadores podem treinar, sem saber, sistemas utilizados para a vigilância e a repressão, como revelou a minha colega Niamh McIntyre, ou fazer checagem de fatos para uma rede social como o Facebook, como mostrei. Traçando um paralelo com a Revolução Industrial, é como se o trabalhador estivesse apertando um parafuso repetidamente, sem saber que o parafuso seria mais tarde utilizado para construir uma bomba.
Para fazer uma reportagem sobre essa indústria, é preciso saber que a cadeia de trabalho é extremamente opaca e secreta. Os trabalhadores assinam termos de confidencialidade muito rígidos e muitas vezes não podem nem mesmo se organizar em grupos ou falar sobre suas experiências na plataforma. As empresas não têm qualquer interesse em revelar os seus processos ocultos. Desta forma, conseguem controlar os pagamentos e os processos de trabalho e impedir os trabalhadores de se organizarem. É aí que entra o jornalismo — na busca do impacto humano.
Compreender a cadeia de produção
O fluxo de dados de formação utilizados nos modelos de IA é uma cadeia de produção: os trabalhadores estão numa ponta, as empresas intermediárias que os contratam por tarefa estão no meio e na outra ponta estão as empresas de tecnologias, ou seja, os criadores de sistemas de IA que necessitam dos dados.

Para começar a investigar, é preciso primeiro compreender os intermediários na cadeia: quais são as empresas de treinamento de dados e com que empresas de tecnologia elas têm contratos? É possível encontrar esta informação em publicações de veículos especializadas em tecnologia e IA, bem como através da própria divulgação das empresas e demonstrações financeiras. Assim, você entenderá quem são os grandes intermediários no mercado de dados.
Mas como se descobre informações sobre o trabalho em si, ou seja, para que tarefas as empresas estão contratando? Nos sites das plataformas, a única informação pública disponível sobre as tarefas são os próprios anúncios de emprego, divulgados como “projetos". No entanto, os apelidos e códigos crípticos desses projetos ocultam o objetivo e o contratante. Apenas são apresentadas descrições genéricas como "encontrar conteúdos falsos", "contribuir para uma Internet mais segura" ou "melhorar as tecnologias".
Identificar o outro extremo da cadeia, os trabalhadores, também não é uma tarefa simples. A boa notícia é que já existem muitos pesquisadores nesta área e iniciativas que podem ajudar com referências e contactos.
Recebi orientações valiosas do psicólogo e pesquisador brasileiro Matheus Viana Braz, autor de vários estudos sobre micro-trabalho. Braz me ajudou a encontrar dezenas de grupos de apoio online nos quais os trabalhadores já se estavam organizando. Existem também várias iniciativas em todo o mundo, como a Data Workers Inquiry, a AI Kenya e a Fairwork, que têm articulado iniciativas consistentes de pesquisa e defesa dos trabalhadores de dados.
Embora seja formalmente proibido falar sobre as tarefas fora das plataformas, os trabalhadores se organizam em grupos e fóruns nas redes sociais. Estudos mostram que é nesses espaços que os trabalhadores podem se apoiar, compartilhar dicas e até melhorar a qualidade do trabalho realizado, já que a maioria dos projetos não têm treinamento adequado.
Por causa dos termos de uso rigorosos e do receio dos trabalhadores de serem banidos, a maioria não está interessada em falar com jornalistas. Uma das razões é o receio de popularizar o trabalho — o que poderia torná-lo mais competitivo e, consequentemente, fazer baixar o salário. A outra razão é o medo óbvio de vazar qualquer informação e, assim, ser punido por quebrar o acordo de confidencialidade da empresa.

Para identificar os contratantes destes trabalhadores e as suas condições de trabalho, foi necessário construir uma base de dados desde a raiz e, assim, mapear toda a cadeia.
A minha base de dados começou com a única informação pública disponível: os anúncios de emprego para os projetos. Pedi ajuda a Federico Acosta Rainis, especialista em dados do Pulitzer Center, para recolher informação pública de todos os anúncios de emprego publicados pelas principais plataformas de trabalho de dados: o nome do projeto, o país, a tarefa e o pagamento. Comecei a organizar essas informações, recolhendo dezenas de ofertas de emprego remoto postadas nos sites das plataformas.
Cada oportunidade postada representa uma "tarefa" isolada, escondida por "projetos" que dão ao intermediário a capacidade de esconder cada extremidade da cadeia uma da outra.
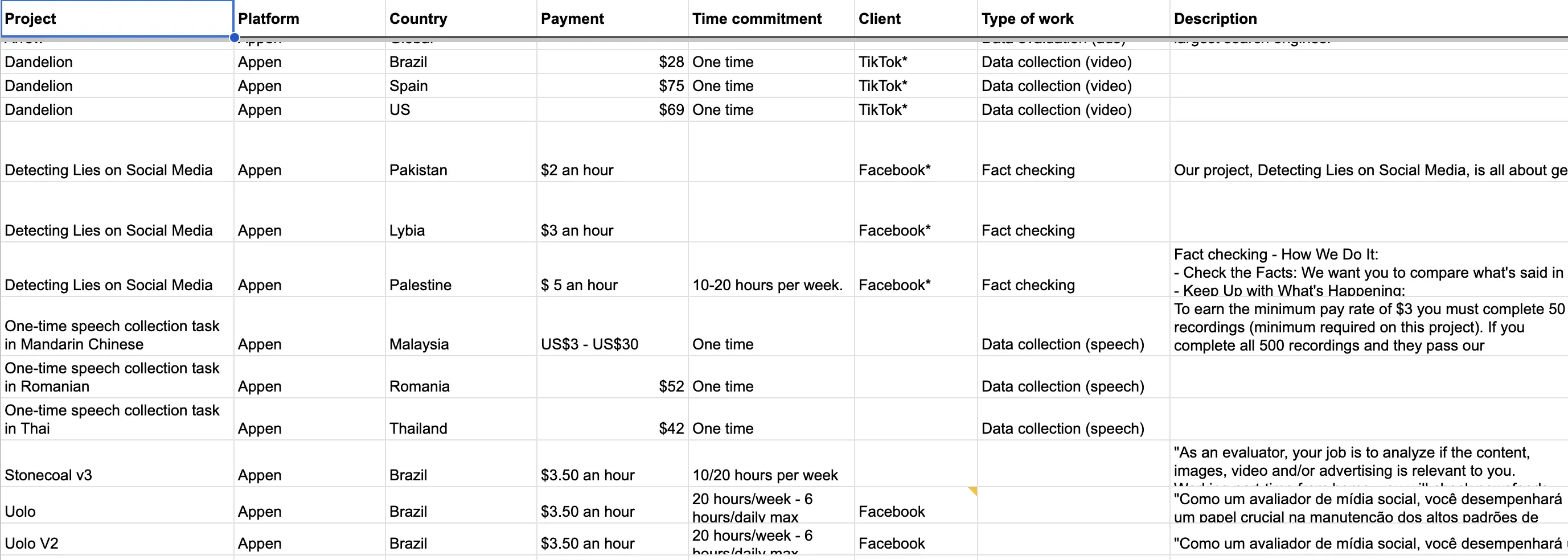
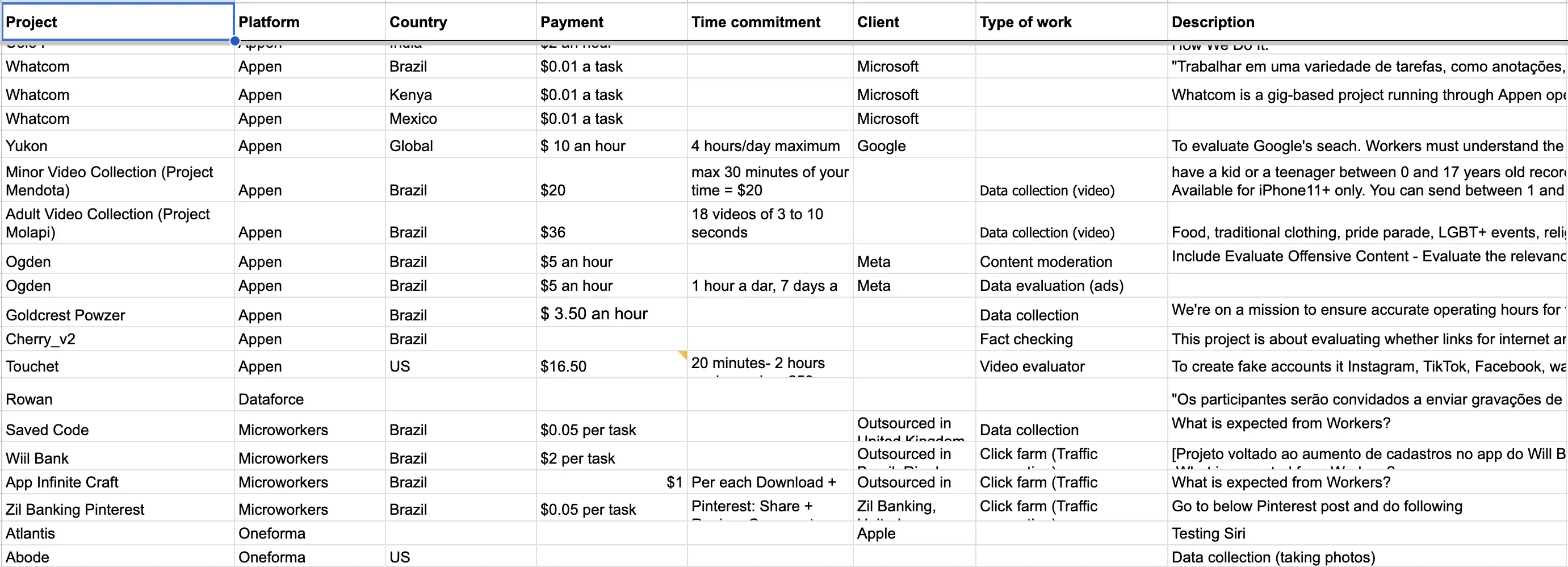
Para identificar os clientes de cada projeto, um método eficaz que encontrei foi olhar diretamente para as tarefas executadas pelos trabalhadores. A minha parceira Sofia Schurig e eu entramos em dezenas de grupos de trabalhadores no WhatsApp, Telegram e Facebook. Nos apresentamos como jornalistas, mas, inicialmente, ninguém quis nos dar entrevistas. Também tentamos enviar uma pesquisa com perguntas, mas a taxa de respostas foi muito baixa.
Ainda assim, como ninguém baniu nossa presença naqueles espaços, começamos a seguir as conversas, os problemas e as rotinas dos trabalhadores. Aos poucos, fomos conhecendo os nomes dos projetos e compreendendo qual era exatamente a tarefa executada.

O projeto Uolo da Appen, por exemplo, é tão popular no Brasil que existem grupos de apoio exclusivamente dedicados a ele. O objetivo do projeto é treinar um sistema de IA para checar informações. Mas o que é essa informação? E quem é o contratante desses projetos?
Nos grupos, conhecemos os desafios dos trabalhadores nesse projeto — uma delas, o fato de terem de determinar se uma determinada publicação era verdadeira ou falsa em pouco mais de um minuto. Para dar um número exato, os trabalhadores tinham de verificar pelo menos 40 conteúdos numa hora — uma média de 1 minuto e 41 segundos por cada publicação. Analisando os comentários e as prints de tela publicados pelos trabalhadores, apuramos que as publicações e os anúncios provinham do Instagram e do Facebook.
Eu sabia que a Meta era cliente da Appen por meio de notícias, mas não sabia exatamente o que os trabalhadores dos dados faziam para o gigante da tecnologia até ver os prints, documentos de treinamento e as URLs do sistema interno do Facebook usado para o trabalho nos grupos de apoio.

Mas nem a Appen nem a Meta confirmaram a existência de um contrato entre as duas entidades quando questionadas. Como eu podia, então, checar se os anúncios e as tarefas eram autênticos? Comecei a verificar os prints dos anúncios que os trabalhadores tinham compartilhado, comparando-os com a biblioteca de anúncios da Meta. Havia anúncios idênticos aos que circulavam no sistema interno dos trabalhadores.
Quando percebi que os trabalhadores estavam checando informação sensível, como posts sobre as cheias catastróficas que assolaram o sul do Brasil em maio de 2024, cheguei à minha primeira história: "Moderadores Subterrâneos: Meta treina inteligência artificial no Brasil pagando menos de um dólar para checar fatos sobre enchentes, violência e política".
A participação nos grupos também revelou os problemas que os trabalhadores enfrentam no trabalho: insegurança, falta de formação, questões técnicas e barreiras linguísticas. Os trabalhadores também se depararam com inúmeros casos de falta de pagamento ou receberam pagamentos inferiores ao esperado.
Com o tempo, comecei a compreender o quotidiano dos trabalhadores: que horas trabalhavam, o que pensavam do trabalho, os seus sonhos e as suas lutas. Havia pessoas nos grupos que só trabalhavam à noite. Outros estavam dispostos a ajudar os recém-chegados. Eu queria entender como funcionava a rotina de trabalho e quais os mecanismos de controle que as empresas tinham sobre essas pessoas.
Analisamos meses de mensagens para descobrir histórias sobre as rotinas dos trabalhadores e publicámos os seus testemunhos anonimamente para proteger a sua privacidade. A segunda história da série surgiu a partir desta investigação: "O Proletariado da Plataforma: Como a indústria da inteligência artificial lucra com uma classe trabalhadora digital desprotegida no Brasil".
Depois de alguns meses, com vários contatos nos grupos de apoio, começamos a receber materiais de treinamento, bem como termos de uso e de confidencialidade. A obtenção destes documentos foi crucial para compreender as regras, a formação de novos trabalhadores. No entanto, tínhamos de ter em mente que os trabalhadores podiam correr riscos legais, de segurança ou ser despedidos. Por isso, fomos cautelosos nas nossas comunicações — em vez de pedirmos documentos confidenciais ativamente, deixamos a porta aberta para que as pessoas partilhassem o que considerassem relevante nas nossas conversas. Funcionou.
Um dos contratos, por exemplo, era particularmente severo sobre o vazamento de informações internas.. O documento também pedia aos trabalhadores que renunciassem a qualquer direito de reclamação em caso de exposição a conteúdos explícitos.


A maioria dos documentos confidenciais que obtivemos contém marcas d’água que poderiam pôr em risco o anonimato de uma fonte. Por esse motivo, optamos por não os publicar. No entanto, como era do interesse público revelar o que diziam, publicámos uma terceira história da nossa série: "Moderadores recebiam 7 cêntimos por tarefa para vasculhar violência, pornografia e conteúdo extremo no X". O artigo baseou-se nos documentos que recebemos e em testemunhos anónimos de trabalhadores.
Ainda há muito para investigar
Desde o início, um dos meus objetivos foi mostrar quem são os principais clientes da classificação de dados para treinar IA. É por isso que considerei crucial traçar a cadeia de comando de uma ponta à outra. A resposta à minha pergunta tornou-se clara: quem contrata esse trabalho, precário e pago com centavos, são as grandes empresas de tecnologia.
A classificação de dados é mais complexa do que o rótulo "microtarefas" sugere. Estes trabalhadores fazem parte de uma indústria multibilionária e merecem ser reconhecidos e adequadamente compensados pelo seu trabalho. Além disso, é importante sublinhar que as condições de trabalho afetam diretamente a qualidade dos dados produzidos e, consequentemente, os resultados gerados pelos sistemas de IA.
Um sistema de checagem de fatos mal treinado produzirá maus resultados em grande escala, o que dificilmente será rentável a longo prazo. Quando falamos discutimos transparência e responsabilização na cadeia de IA, devemos pensar em todo o processo: desde a forma como os dados são produzidos e como os sistemas são treinados até aos potenciais riscos e preconceitos que os trabalhadores enfrentam. Os trabalhadores que estão na linha da frente devem fazer parte desta conversa.
Muitas perguntas continuam sem resposta. Olhando para as tarefas, é possível perceber algumas tendências na indústria da IA. Alguns projetos, por exemplo, pagam aos trabalhadores por fotografias de crianças. Sim, fotografias de crianças. Outros pagam por fotos de documentos de identidade. Por que a indústria da IA precisa de um número colossal de documentos pessoais? E como a privacidade desta vasta quantidade de dados será tratada?
Outro ponto que vale a pena mencionar é que algumas grandes empresas de tecnologia, como a Kwai e a TikTok, estão incorporando direto em suas plataformas a contratação de trabalhadores de dados, como moderadores, para treinar IA. Uma reportagem publicada no Brasil mostrou que crianças e adolescentes estão "viciados" nesse tipo de tarefa, que rende centavos e os mantém grudados nas plataformas por horas.
Embora a questão do trabalho humano seja, a meu ver, uma das mais urgentes em termos de IA, ela ainda é ignorada na maioria das iniciativas regulatórias. No Brasil, apesar de o Ministério do Trabalho e Emprego ter criado um grupo de trabalho para discutir o trabalho com dados, o tema sequer foi incluído na regulamentação da IA aprovada pelo Senado em novembro de 2024.
Esta não interferência parte do princípio de que a IA surge por magia ou simplesmente por meio próprias máquinas, sem apoio humano — uma ideia que, como tentei demonstrar nas minhas reportagens, não é verdadeira. Muitos humanos estão alimentando essa máquina. A indústria quer escondê-los — mas um dos papéis do jornalismo na responsabilização pela IA é mostrar que eles existem.