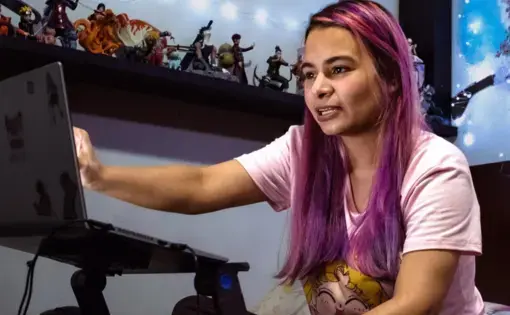Much of the public discourse examining AI development today has centered on the U.S.: in particular, on how Silicon Valley’s profit motives have driven AI research and its repercussions. This account misses a far more global story. Silicon Valley may still be where most AI algorithms are developed—but the data those algorithms are trained on is being gathered in another country, labeled in a third, and used to develop models deployed in a fourth.
Which parts of the development pipeline happen in which countries has much to do with colonial history. Countries with less power (former colonies) have less advanced data privacy regulation and thus bear the brunt of massive data collection. They have cheaper labor and thus get saddled with menial data labeling. They lack resources to develop their own AI and thus must cope with AI not constructed for them. Meanwhile, countries with more power (former colonial powers) disproportionately reap the technology’s economic rewards.
In a four-part series, Karen Hao illustrates these uneven impacts through the eyes of people experiencing them around the world. She brings readers to Kenya, where a data labeling industry has blossomed, and to Indonesia, where ride-hailing drivers are organizing against their routing algorithms.
So much of the discourse around AI development focuses on how to build “AI for everyone.” But we lack a grounded understanding in what that means or looks like. By revealing the overlooked ways that AI benefits some at the expense of others, we gain a better understanding of how to course-correct the technology.
Image caption: Data annotators discussing the correct labeling of a dataset. Image by Nacho Kamenov & Humans in the Loop/Better Images of AI/ CC-BY 4.0