





Every year, millions of welfare benefits recipients across Europe are profiled for fraud by opaque...
Obscure government algorithms are making life-changing decisions about millions of people around the world. Here, for the first time, we reveal how one of these systems works.
EVERY YEAR, THE city of Rotterdam in the Netherlands gives some 30,000 people welfare benefits to help them make rent, buy food, and pay essential bills. And every year, thousands of those people are investigated under suspicion of committing benefits fraud. But in recent years, the way that people have been flagged as suspicious has changed.
In 2017, the city deployed a machine learning algorithm built by consulting firm Accenture. The algorithm, which generates a risk score for everyone on welfare, was trained to catch lawbreakers using data about individuals who had been investigated for fraud in the past. This risk score is dictated by attributes such as age, gender, and Dutch language ability. And rather than use this data to work out how much welfare aid people should receive, the city used it to work out who should be investigated for fraud.

As a nonprofit journalism organization, we depend on your support to fund more than 170 reporting projects every year on critical global and local issues. Donate any amount today to become a Pulitzer Center Champion and receive exclusive benefits!
When the Rotterdam system was deployed, Accenture hailed its "sophisticated data-driven approach" as an example to other cities. Rotterdam took over development of the algorithm in 2018. But in 2021, the city suspended use of the system after it received a critical external ethical review commissioned by the Dutch government, although Rotterdam continues to develop an alternative.
By reconstructing the system and testing how it works, we found that it discriminates based on ethnicity and gender.
Lighthouse Reports and WIRED obtained Rotterdam’s welfare fraud algorithm and the data used to train it, giving unprecedented insight into how such systems work. This level of access, negotiated under freedom-of-information laws, enabled us to examine the personal data fed into the algorithm, the inner workings of the data processing, and the scores it generates. By reconstructing the system and testing how it works, we found that it discriminates based on ethnicity and gender. It also revealed evidence of fundamental flaws that made the system both inaccurate and unfair.
Rotterdam’s algorithm is best thought of as a suspicion machine. It judges people on many characteristics they cannot control (like gender and ethnicity). What might appear to a caseworker to be a vulnerability, such as a person showing signs of low self-esteem, is treated by the machine as grounds for suspicion when the caseworker enters a comment into the system. The data fed into the algorithm ranges from invasive (the length of someone’s last romantic relationship) and subjective (someone’s ability to convince and influence others) to banal (how many times someone has emailed the city) and seemingly irrelevant (whether someone plays sports). Despite the scale of data used to calculate risk scores, it performs little better than random selection.
Machine learning algorithms like Rotterdam’s are being used to make more and more decisions about people’s lives, including what schools their children attend, who gets interviewed for jobs, and which family gets a loan. Millions of people are being scored and ranked as they go about their daily lives, with profound implications. The spread of risk-scoring models is presented as progress, promising mathematical objectivity and fairness. Yet citizens have no real way to understand or question the decisions such systems make.
Governments typically refuse to provide any technical details to back up claims of accuracy and neutrality. In the rare cases where watchdogs have overcame official stonewalling, they've found the systems to be anything but unbiased. Reports have found discriminatory patterns in credit scoring, criminal justice, and hiring practices, among others.
Being flagged for investigation can ruin someone’s life, and the opacity of the system makes it nearly impossible to challenge being selected for an investigation, let alone stop one that’s already underway. One mother put under investigation in Rotterdam faced a raid from fraud controllers who rifled through her laundry, counted toothbrushes, and asked intimate questions about her life in front of her children. Her complaint against investigators was later substantiated by an official review.
The opacity of the system makes it nearly impossible to challenge being selected for an investigation.
But how did the algorithm decide who to investigate? And how did it make those decisions? To work this out, we created two hypothetical people, or archetypes: “Sara,” a single mother, and “Yusef,” who was born outside the Netherlands. Their characteristics and the way they interact with Rotterdam’s algorithm show how it discriminated when scoring real people.
FEEDING THE MACHINE
Here's how the city's welfare algorithm reduces a struggling mother's complex life into simplified data.
Imagine “Sara,” a hypothetical single mother of two children. She recently broke up with her partner. When one of her sons fell ill four months ago, she quit her job to take care of him. She now runs out of money to pay her bills before the end of each month.
At their last meeting, Sara’s caseworker noted in her file that "clothing, makeup, and/or hairstyle are unsuitable for job application" and that she was struggling to deal with setbacks because of a lack of flexibility.
Even these subjective observations influence the fraud algorithm.

Discriminating against people based on their gender and ethnic background is illegal in the Netherlands, but converting that information into data points to be fed into an algorithm may not be. This gray area, in part the result of broad legal leeway granted in the name of fighting welfare fraud, lets officials process and profile welfare recipients based on sensitive characteristics in ways that would otherwise be illegal. Dutch courts are currently reviewing the issue.
Rotterdam's algorithm doesn't explicitly include race, ethnicity, or place of birth among the 315 attributes, or variables, it uses to calculate someone’s risk score. More than half of the city’s residents are first- or second-generation migrants. Some of those variables can be proxies for ethnicity.
Rotterdam’s director of income, Annemarie de Rotte, says the city attempted to remove some proxy variables related to ethnicity following the external audit, but some remained in the system. For example, everyone who gets welfare in the Netherlands is required to speak Dutch or be able to prove they are making an effort to do so. This language requirement, as well as someone having a native language other than Dutch, can be proxies for ethnicity. Having financial problems and multiple roommates can also be proxies for poverty. This is how proxies work in the case of Yusef.
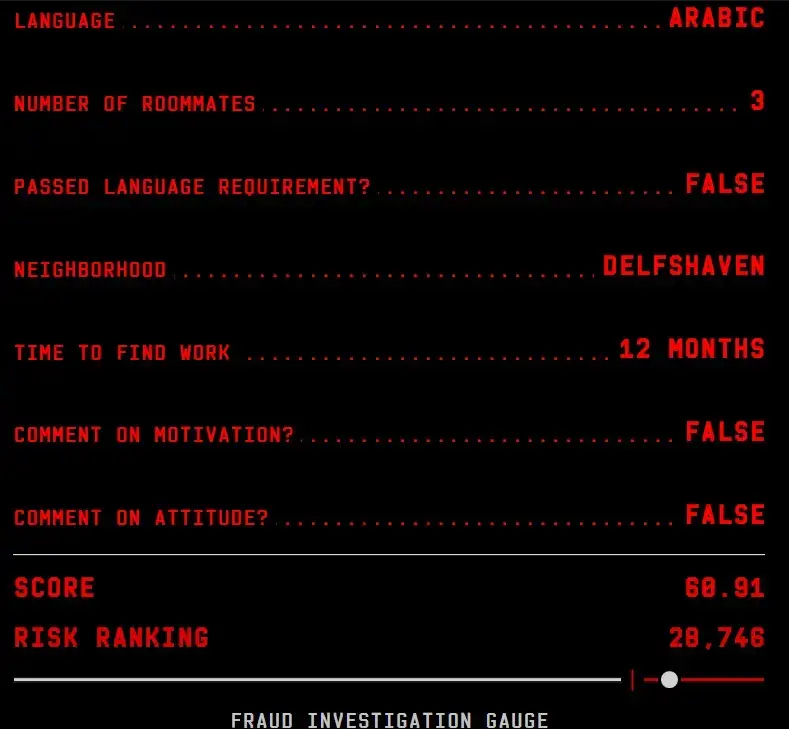
Now imagine another hypothetical Rotterdam resident, “Yusef,” who immigrated to the Netherlands from Iraq. He currently lives in a Rotterdam neighborhood with a large migrant population. He shares a flat with other Iraqis who he has met since arriving in the city.
Yusuf’s first language is Arabic, and he has not passed his Dutch language exam.
Yusef was a teacher in Iraq, but his caseworker is skeptical that he will be able to get his college degree recognized in the Netherlands. She thinks he should try to get a job as a dock worker instead.
In his file, Yusef's caseworker notes that he “shows no desire to achieve results” and that he seems dispirited.

The Dutch government recognizes that language skills can be a proxy for ethnicity. In its analysis of the variables used by the Rotterdam algorithm, the Netherlands Court of Audit, an independent body appointed by the Netherlands’ government, pointed to “fluency in the Dutch language” as an example of a variable that could “result in unwanted discrimination.” The algorithm also judges people based on their native language, with different languages given different numbers, each with a different impact on someone’s final risk score. When asked what a “0” meant for this variable, which is what half the people in the data have for this field, de Rotte says the city does not know.
Risk-score algorithms, like the one used in Rotterdam, are often accused of encoding human bias—but proving that is difficult. Once you have the code and the data that powers it, however, you can start to unpack how this process works. For example, Rotterdam’s algorithm has 54 variables based on subjective assessments made by caseworkers. This amounts to 17 percent of total variables, each with varying impacts on the score.
To view the interactive "Risk Ranking" graphic, visit WIRED.com.
The use of these subjective assessments raises ethical red flags for many academics and human rights advocates. “Even when the use of the variable does not lead to a higher risk score, the fact that it was used to select people is enough to conclude that discrimination has occurred,” says Tamilla Abdul-Aliyeva, a researcher on technology and human rights at Amnesty International.
And it’s not just the inclusion of subjective assessments that is cause for concern—such systems also take nuanced information and flatten it. The comment field in the Rotterdam system, for example, where caseworkers are asked to make general observations, is binary. Any comment is converted to a "1," while a blank field is converted to a "0." This means negative and positive comments affect the score in the same way. If, for example, a caseworker adds a comment that reads “shows no desire to achieve results,” it has the same effect on the risk score as a comment that reads “shows desire to achieve results.” The manual given to caseworkers for evaluating beneficiaries makes no mention of their notes being fed into the risk-scoring algorithm, nor that positive and negative comments will be read the same.
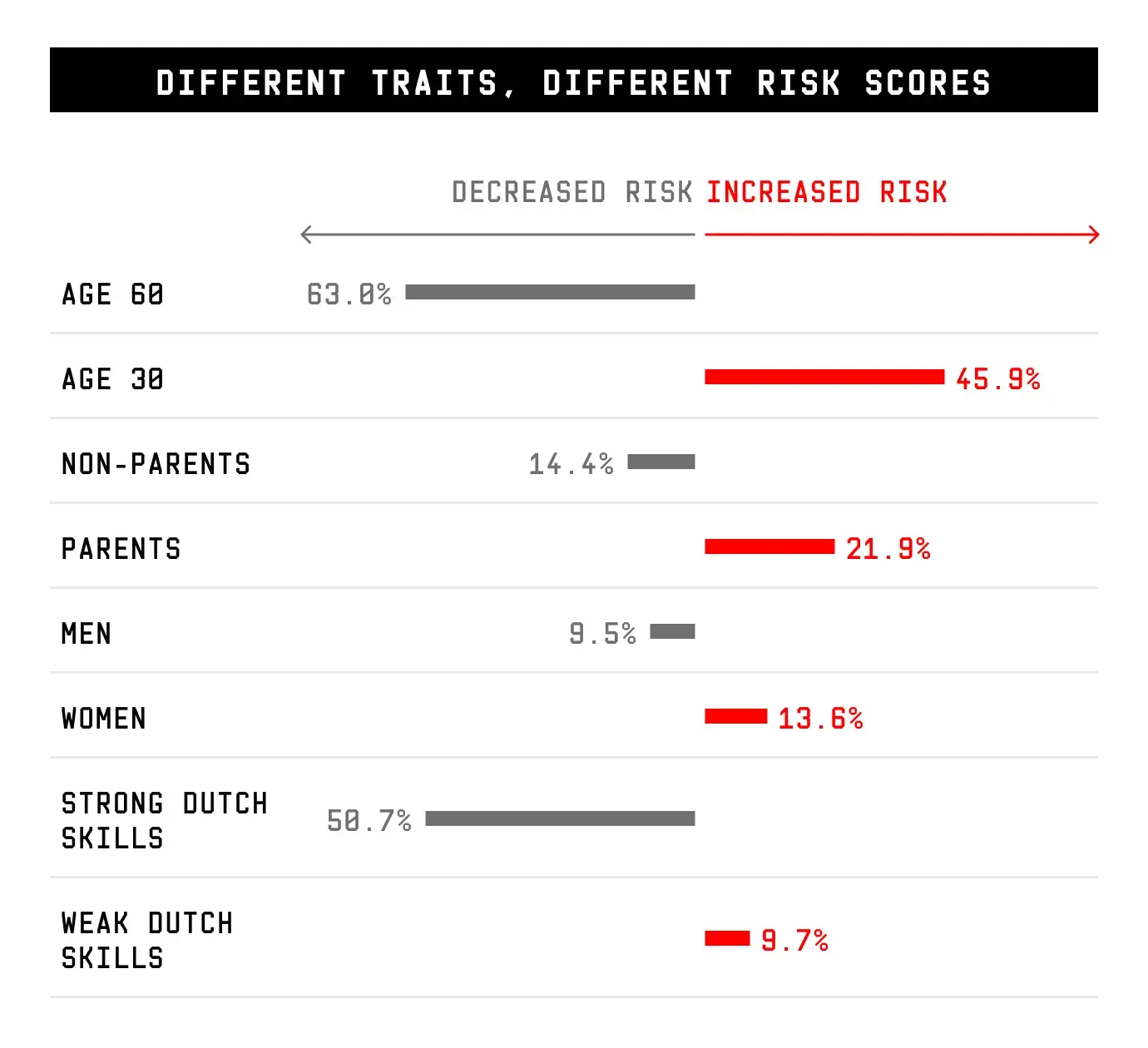
Of the 30,000 welfare recipients in Rotterdam, roughly the top 10 percent, or everyone ranked above 27,000 on the list, are at risk of being investigated.
Imagine a typical 30-year-old male born in Rotterdam who receives social welfare to make ends meet. He ranks 16,815 on the list, with over 10,000 people between him and a potential investigation into benefits fraud.
Let's compare his likelihood of being investigated to Sara's by adjusting key attributes about him until, to the algorithm, he becomes Sara.
If our typical Rotterdam male were female, she'd move up 4,542 spots closer to a possible investigation.
If she had two children, she would move another 2,134 spaces up the list.
If she were single, but coming out of a long-term relationship, that's another 3,267 spots.
Struggling to pay bills? That's another 1,959 places closer to potential investigation.
For the suspicion machine, the typical male welfare beneficiary in Rotterdam is now identical to Sara and is likely to be investigated for benefits fraud.






To the algorithm, Sara differs from the average male based on just eight of the 315 variables each person is judged on, yet she is nearly three times more likely to be flagged as a potential fraudster. The gap in their two scores, despite them having data that mostly overlaps, stems from how the machine makes links between certain traits.
So what happens if we adjust the attributes of our average Rotterdam man to make him more like Yusef? Remember, there are over 10,000 people between the average man and a fraud investigation to begin with.
If he were a migrant, who, like Yusef, spoke Arabic and not Dutch, he would move up 3,396 spots on the risk list. If he too lives in a majority migrant neighborhood in an apartment with roommates, he would move 5,245 spots closer to potential investigation.
If his caseworker is skeptical he will find a job in Rotterdam, he'd move up another 3,290 spots.
With just five changes, he’s now likely to be flagged for investigation.

From face recognition software that performs poorly on people of color to hiring algorithms that screen out women, poor training data can create machine learning models that perpetuate biases. And the Rotterdam training data is seemingly no different.
It contained information on 12,707 people who had previously been investigated by the city, half of whom were found to have broken the law. From this data, the algorithm tries to work out what distinguishes someone who is committing welfare fraud from someone who is not. But an algorithm is only as good as the data it is trained on—and Rotterdam’s data was flawed.
Say, as a theoretical example, most men in the training data were selected at random, while most women were investigated following tips from neighbors or hunches from caseworkers. In this scenario, the data might show that women on welfare are much more likely to commit fraud than men, without considering whether women, generally, are more likely to commit fraud. Without seeing the full picture, the algorithm would learn to associate women with fraud.
Rotterdam uses random selection, anonymous tips, and category checks that change every year (checking all men in a particular zip code, for example) to start investigations, with data from all three approaches used to train the algorithm. Rotterdam’s de Rotte declined to provide detailed information on how individuals in the training data were selected for investigation. Although the city was running the algorithm, it continued using random selection and category checks alongside risk scores to choose who to investigate and what to feed into the training data. “If a training data set [contains] systemic biases, then the algorithmic output will always re-create these inequalities,” says Julia Dressel, an expert in the use of technology in criminal justice systems.
Some groups barely show up in Rotterdam’s training data. There should have been around 880 young people in the data to reflect the actual proportion of people under the age of 27 who receive welfare in the city. Instead, there were only 52. In our tests of the algorithm, it was age, specifically youth, that was the most significant attribute in raising risk scores. To the algorithm, it appeared as if young people are more likely to commit welfare fraud, but it drew that conclusion based on a sample size so small it was effectively useless.
FORK IN THE ROAD
Data scientists build risk models to scour large amounts of data to uncover hidden patterns. While the machine learning algorithm used in Rotterdam’s system, called a gradient boosting machine, relied on complex mathematics to uncover these patterns, its basic building block is a decision tree.
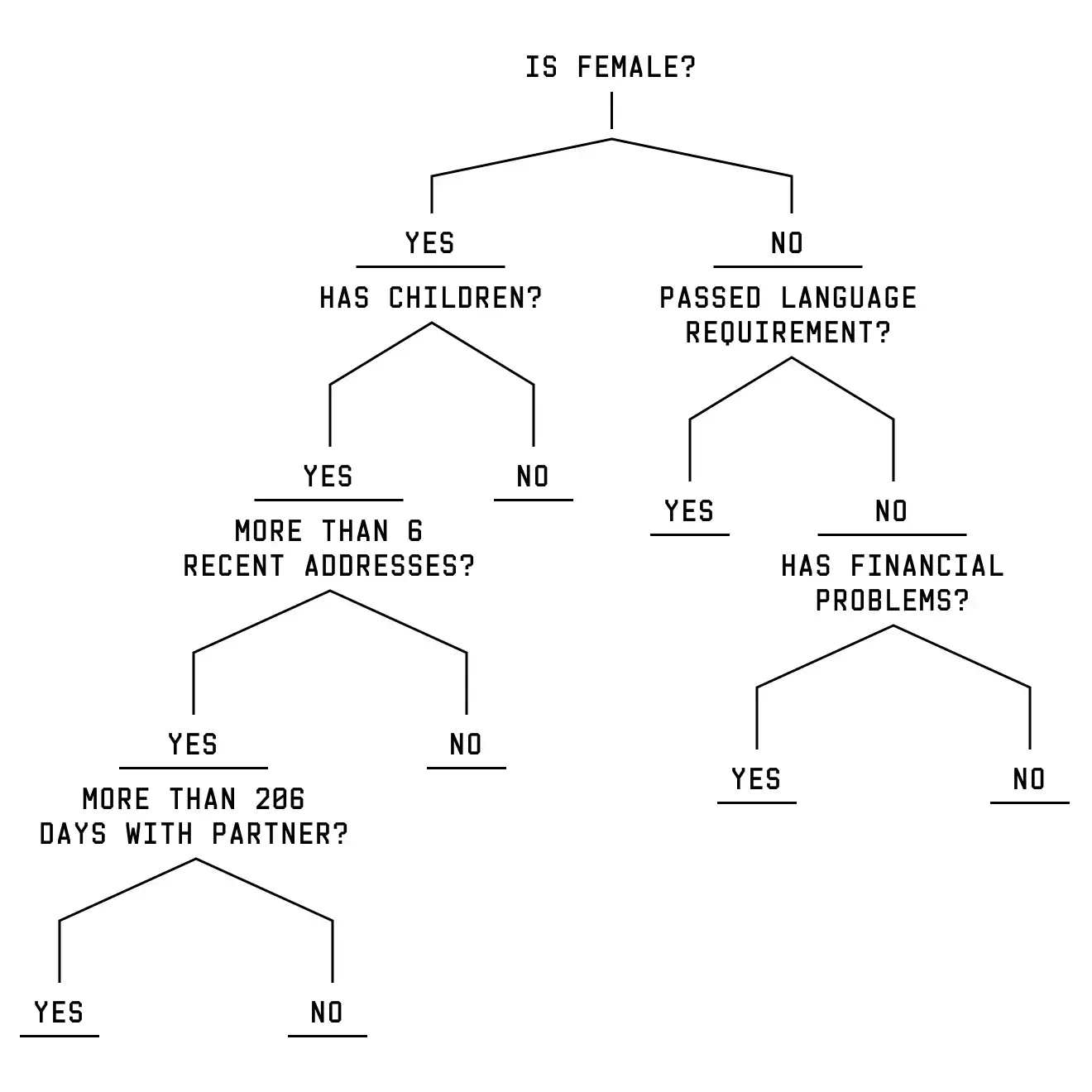
Rotterdam’s algorithm is made up of 500 decision trees. These trees categorize individuals based on a series of yes-no questions. At each question, a person can travel down the left or right branch until they reach the bottom of the tree. With no questions left, the decision tree gives that person a value. The values of all the 500 trees powering Rotterdam’s algorithm are combined to calculate a person’s risk score.
The real decision trees in the model contain many variables and branches. To understand how Sara and Yusef’s scores are generated, Sara is going to travel down a simplified decision tree. Sara is the mother of two children. She recently moved into a new apartment after splitting up with her long-term partner. You can see how these attributes send Sara down a specific branch of a decision tree.
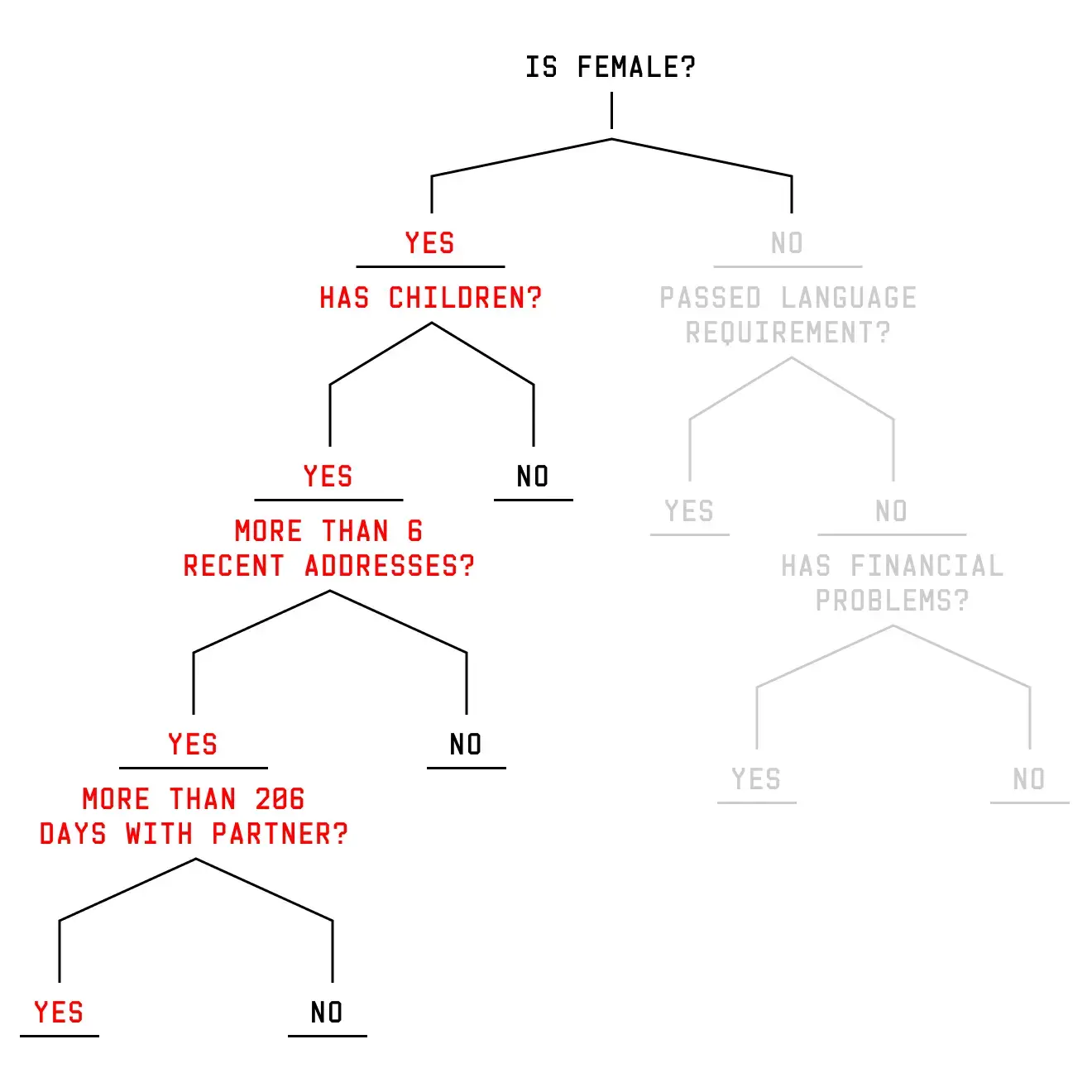
But what happens if Sara is male rather than female? As a woman, Sara is asked about her relationship status, children, and living situation. As a man, Sara is sent down an entirely different branch with entirely different questions. Two people, two different paths, and two different sets of questions. But we changed just one attribute: gender.
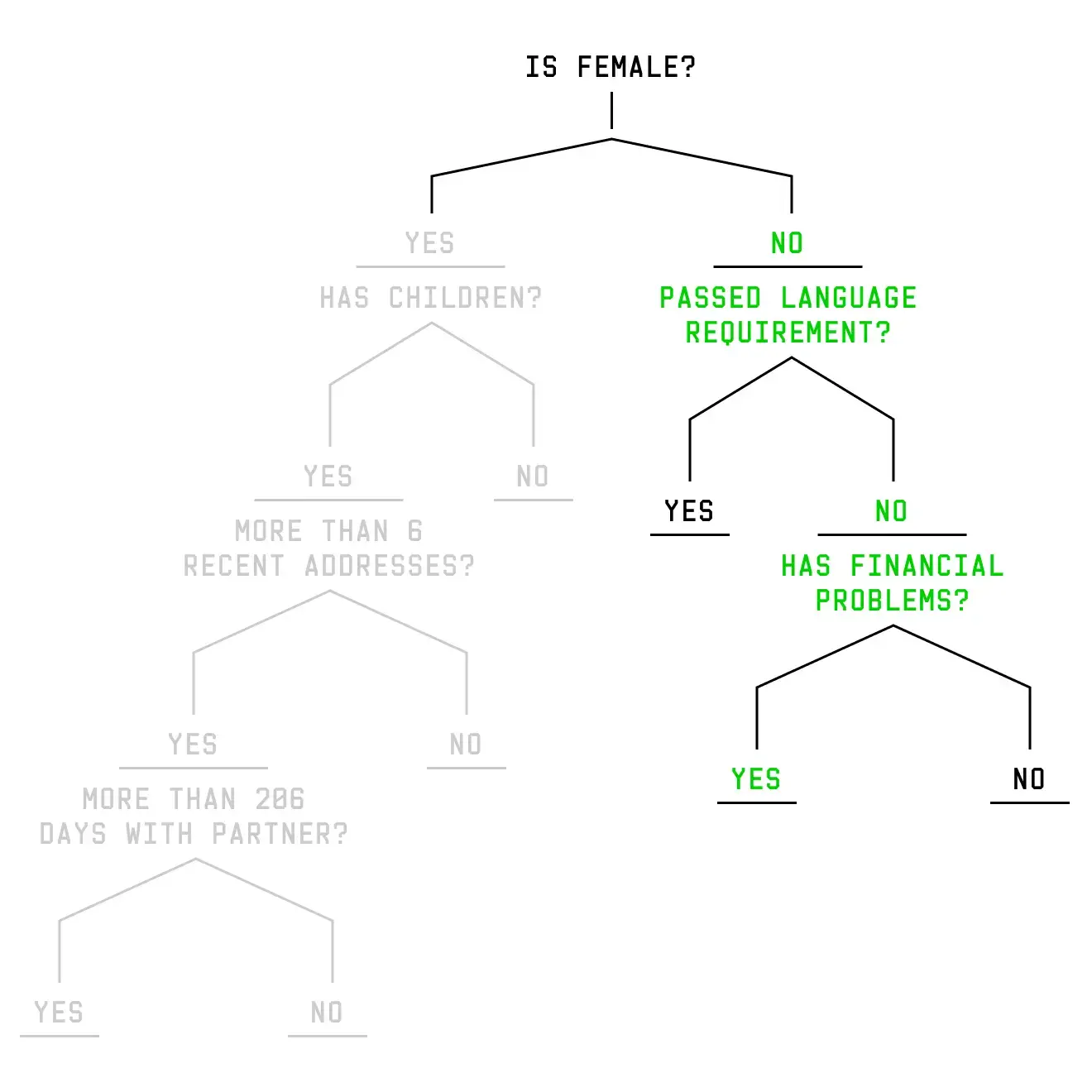
Using decision trees makes it hard to understand how any single variable affects how people are scored. Take gender in the example above: Men and women move down separate branches of the decision tree, and different variables are used to assess their risk. Men, for example, may be evaluated for their language skills and financial standing, while women could be scored on whether they have children or if they are in a relationship. As a result, being male may increase the risk score for some and decrease it for others.
Changing even a few variables can drastically change the score of an average welfare recipient. You can switch the toggles on the case profile to see how this works.
Switching certain toggles, such as age and gender, has a massive impact on someone's risk ranking—and can push them over the red line, triggering a potential fraud investigation.
To view the interactive "Case Profile" graphic, visit WIRED.com.
Rotterdam's welfare-fraud algorithm is trained on millions of data points, but it is blind to what is actually happening in the real world. In reality, different people commit different kinds of violations—from honest mistakes when filling out a form to organized crime. Rotterdam itself says that many legal violations stem from a law that requires small changes in a beneficiary’s living situation and finances to be reported immediately through a process many beneficiaries do not understand.
But the algorithm learns to make its predictions based on a pattern it extrapolates from the training data that collapses honest mistakes and deliberate fraud into one category: fraud. It tries to find commonalities between people making paperwork mistakes and people deliberately trying to cheat the system. The consequence is that it is not very good at predicting either. “The algorithm converts ‘honest mistakes’ into learned associations between poor Dutch skills and propensity for fraud, allowing welfare officials to claim that migrants who do not speak Dutch are scientifically untrustworthy,” says Dressel.
Flaws in the training data and design of the algorithm combine to create a system that is alarmingly inaccurate, experts claim. “It's not useful in the real world,” says Margaret Mitchell, chief ethics scientist at AI firm Hugging Face and a former AI ethicist at Google. According to Mitchell, Rotterdam’s own performance evaluation indicates the model is “essentially random guessing.”
Assessing an algorithm means looking not just at whether it is accurate but also whether it discriminates. Was Sara alone in being scored higher for being a single mother, or were single mothers as a group getting higher scores? Was it just Yusef's poor Dutch that made him suspicious, or were most poor speakers of Dutch getting higher scores? It's possible to work out whether the algorithm discriminated against certain groups based on Rotterdam's own internal definition of discrimination. The code for the city’s risk-scoring algorithm includes a test for whether people of a specific gender, age, neighborhood, or relationship status are flagged at higher rates than other groups.
De Rotte, Rotterdam’s director of income, says the city never actually ran this particular code, but it did run similar tests to see whether certain groups were overrepresented or underrepresented among the highest-risk individuals and found that they were. We ran a similar test to Rotterdam’s and found widespread discrimination against several vulnerable groups. In other words, it isn’t just Sara and Yusef being discriminated against, it’s also people like them.
CROSSING THE LINE
We used Rotterdam’s fraud algorithm to calculate the risk scores for both Sara and Yusef as well as more than 12,700 real welfare recipients sourced from the city’s own training data.
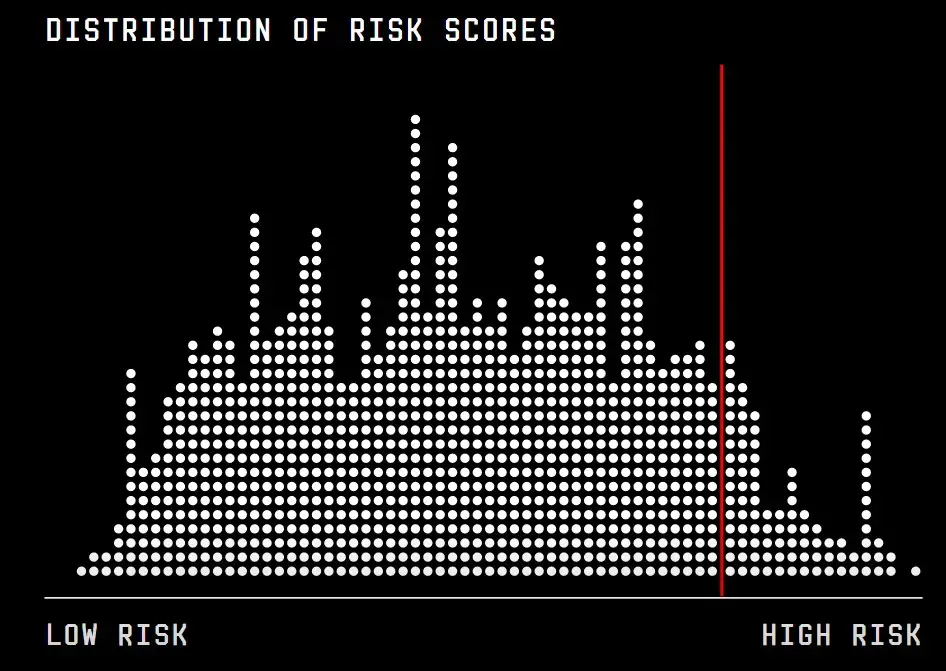
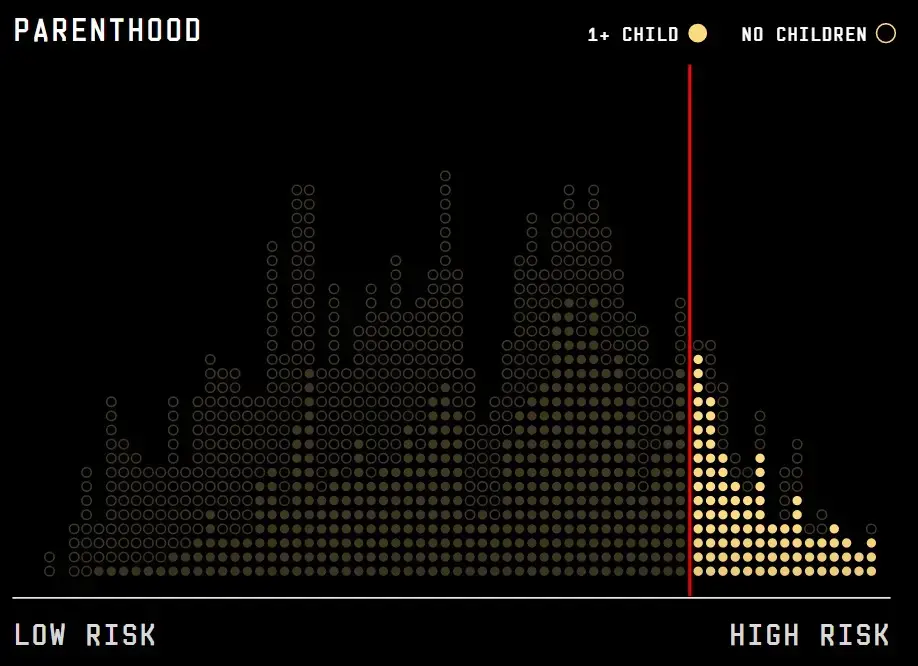
Rotterdam considers the top 10 percent of welfare recipients in this data set to be “high risk." This chart shows the distribution of scores for a random selection of 1,000 welfare recipients. Each dot represents an individual person’s risk score.
Filled circles are people who have not met their Dutch language requirement. Empty circles are people who have.
This line is the cutoff for a person to rank as high risk. People who have not passed a Dutch language requirement are almost twice as likely to be categorized as high risk of committing fraud as those who have passed.
Having children can have a major impact on your risk score. Parents are a little more than two times more likely to be categorized as high risk of committing fraud than non-parents.
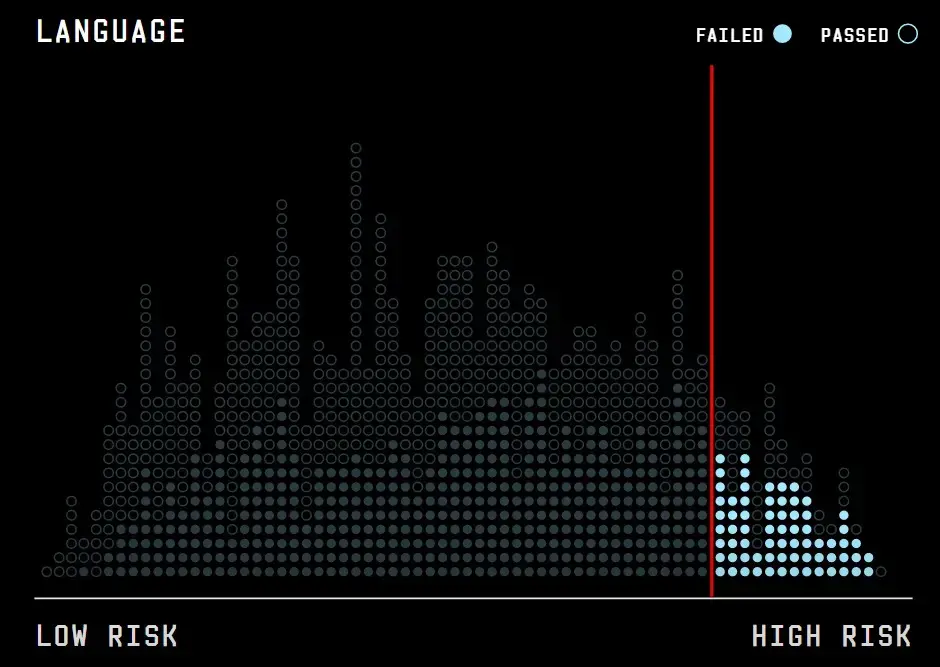
Language has both a large influence on people’s score and is the most obvious proxy for ethnicity used by the algorithm. Rotterdam's algorithm tries to work out how well someone can speak Dutch based on 20 variables. It’s fed data about how well someone can speak, write, and understand Dutch, along with the number of appointments they've had with a caseworker about the language requirement. If someone is rated as struggling with Dutch across these variables, they are two times more likely to be flagged for a welfare fraud investigation than somebody who is fluent in Dutch. Assigning high risk scores based on Dutch fluency means that people who are non-white immigrants are more likely to be investigated. This type of ethnic discrimination by algorithms has been dubbed a digital stop and frisk.
Rotterdam’s internal evaluation documents reveal that its risk-scoring system is so inaccurate that, according to some metrics, it does little better than random sampling. Our experiment also reveals that it discriminates against vulnerable people by scoring them more highly as a result of their vulnerabilities, such as having children or struggling financially. But do women, people who do not speak Dutch, or parents commit welfare fraud more often than people in other groups?
"Models will always be poor estimators of actual risk."
— MARGARET MITCHELL, CHIEF ETHICS SCIENTIST, HUGGING FACE
To know that, Rotterdam needs to share more information. We requested data from the city that would allow us to see whether investigators had found more cases of fraud among specific groups, but officials declined to provide us with that detail on unspecified legal grounds. For now, only Rotterdam knows whether the vulnerable groups its algorithm found suspicious really did break the law more often than other groups.
Based on its own assessment, Rotterdam knew who was getting flagged at higher rates and removed some proxy variables, but kept using the system until finally suspending the algorithm’s use in late 2021. Yet that same year, Rotterdam city councillor Richard Moti insisted there was “no bias in both the input and output” of the algorithm. But no matter what adjustments are made, a mathematical equation can do only so much to accurately spot fraud in the messy reality of how people live. “Models will always be poor estimators of actual risk,” says Mitchell, adding that algorithms are likely to exclude potentially important personal details. “If you took situations case by case, the predictions made by a mathematical model would never capture all of the variables at play in each individual case.”
SUNSHINE IN A BLACK BOX
Rotterdam isn’t the only city using algorithms to interrogate welfare recipients. But it is, to date, the most transparent about what it’s doing. Rotterdam was chosen for this story not because its system is especially novel, but because out of dozens of cities we contacted, it was the only one willing to share the code behind its algorithm. Alongside this, the city also handed over the list of variables powering it, evaluations of the model’s performance, and the handbook used by its data scientists. And when faced with the prospect of potential court action under freedom-of-information laws—European equivalents to US sunshine laws—it also shared the machine learning model itself, providing unprecedented access.
This transparency revealed a system unfit for its intended purpose. In 2017, Accenture, the city’s technology partner on an initial version of the project, promised that “advanced analytics” would be combined with machine learning to create “unbiased citizen outcomes.” In a presentation produced at the time, the consulting firm claimed such a system would help Rotterdam ensure that people in need of help received it and that there would be “a fair distribution of welfare.”
The reality of Rotterdam’s suspicion machine is starkly different. This is an algorithm that fails the city’s own test of fairness—and despite being touted by Accenture as an “ethical solution,” it’s so opaque that it denies due process to the people caught up in it.
“We decided to give you maximum insight into the model, not only because of our desire to be an open and transparent organization but also to be able to learn from the insights of others.”
— ANNEMARIE DE ROTTE, ROTTERDAM'S DIRECTOR OF INCOME
“We delivered a startup model and transitioned it to the city as our contract ended in 2018,” says Accenture spokesperson Chinedu Udezue. The company declined to comment on the historical lack of transparency around the algorithm’s use.
In the real world, thousands of people like Sara and Yusef have suffered the consequences of a flawed algorithm based on flawed data. People flagged by the algorithm as potential fraudsters can, in theory, ask for all the data the city has collected on them. They can ask for their risk score. They can ask for their rank. They can try to ask a city caseworker, a lawyer, or a judge how the suspicion machine decided that those numbers amount to a pattern of illegal behavior. Until now, they have had no way of making sense of those answers.
Rotterdam defends its right to enforce the law but says our investigation has shown the need for greater transparency wherever similar systems are deployed. “[We] consider it very important that other governments and organizations are aware of the risks of using algorithms,” says Rotterdam’s de Rotte. “We decided to give you maximum insight into the model, not only because of our desire to be an open and transparent organization but also to be able to learn from the insights of others.”
Credits
WRITING AND REPORTING: Eva Constantaras, Gabriel Geiger, Justin-Casimir Braun, Dhruv Mehrotra, Htet Aung
DESIGN AND ILLUSTRATION: Kyle Thomas, Alyssa Walker, Katherine Lam
DEVELOPMENT: Raagul Nagendran, Hari Moorthy, Ishita Tiwari, Danielle Carrick, Lily Boyce
EDITING: Andrew Couts, James Temperton, Daniel Howden, Tom Simonite
SPECIAL THANKS: Thanks to Margaret Mitchell (Hugging Face), Alexandra Chouldechova (Carnegie Mellon University), Cynthia Liem (Technical University of Delft), Jann Spiess (Stanford University), Chris Snijders (Technical University of Delft), Nicholas Diakopoulos (Northwestern University), Nripsuta Saxena (University of California), and Nicolas Kayser-Bril (Algorithm Watch) for reviewing our experimental design and methodology.
Reporting was supported by the Pulitzer Center’s AI Accountability Network and the Eyebeam Center for the Future of Journalism.








