Journalist Resource November 11, 2024
Opening the AI 'Black Box': How We Investigated Grab’s Fare System
Country:



Project
The Philippines and the AI Boom
How AI intersects with the systems of disadvantage and discrimination in the Philippines.

Users of Grab, the Philippines' most popular ride-hailing app, are at the mercy of an opaque algorithm that calculates service prices.
When they book a ride, the amount to be paid for the distance traveled and the travel time is usually coupled with a surge fee that, according to the company, "reflects the real-time market conditions" and allows it to balance supply and demand between drivers and users. Grab says that to calculate the final price, the algorithm considers factors such as traffic, location, and the number of available drivers, but does not provide clear explanations as to when the surge fee is applied and exactly how it is calculated.
Our investigation revealed that this extra fee is always present, regardless of the time and location at which a ride is booked, and that paying for more expensive rides does not necessarily result in shorter waiting times. We came to this conclusion after collecting and analyzing thousands of data points.

As a nonprofit journalism organization, we depend on your support to fund more than 170 reporting projects every year on critical global and local issues. Donate any amount today to become a Pulitzer Center Champion and receive exclusive benefits!
The challenge of getting the data
One of the main problems in reporting on proprietary algorithms is the lack of transparency. Grab's pricing algorithm is a classic example of the so-called "black box": The system gets an input, in this case, the pick-up and drop-off locations selected by the user, and then returns an output, the price to be paid.
Between input and output there is a series of calculations involving a number of variables: How many variables are there? What is the weight of each one? What are the calculations performed?
Since we cannot see what happens inside the box, we worked systematically on the inputs and outputs to report this story. We chose a set of inputs (pairs of pick-up and drop-off locations) and held them constant over time, in order to analyze what happened to the outputs.
For one week, we collected data on Grab prices throughout the day for 10 routes in Metro Manila. We collected the data from two different sources: manually from the app itself, simulating the booking of a trip, and automatically through a public Grab API (Application Programming Interface) called Farefeed, which was available in the company's online fare check tool. An API allows you to interact more directly with the code and data of a program, circumventing the user interface, and usually allows you to systematically extract data from the program.
In total, we gathered 1,328 data points from the app and 6,720 from the API. Using two different sources allowed us to complement the limitations of each method and have different variables to analyze the data more thoroughly. Comparing prices from both sources allowed us to confirm that the data were in similar ranges and not off the mark.
To explore the data we collected, click here. Although it only represents a small part of Grab's data, it offers a glimpse into the inner workings of its algorithm.
Manual collection, from Grab’s app
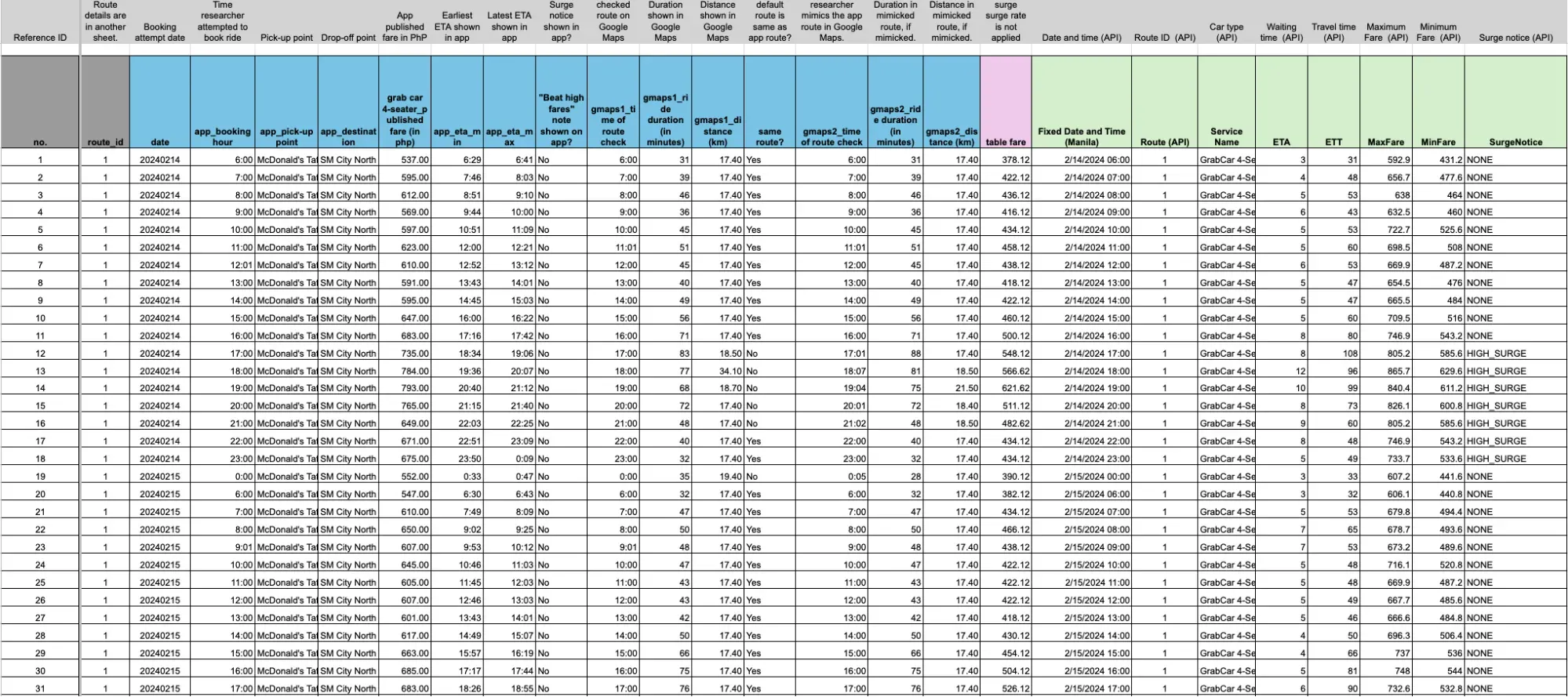
A team of 20 researchers attempted to book rides on 10 routes across Metro Manila every hour from 6:00am to midnight between February 14 and 20, 2024. The last data collected was at 12:00am on February 21, 2024. Taking shifts, two researchers were assigned for each route. We chose pick-up and drop-off locations across different cities in Metro Manila, including train stations, churches, hospitals, malls, universities, city halls, and the like.
The researchers attempted to book the assigned route at the top of the hour, i.e., 6:00am, 7:00am and so on, to match the automatic data collection (see below). At each booking attempt, they took screenshots of the app's booking page with information about the fare for a GrabCar four-seater, the estimated time of arrival at the destination, and the suggested route.

After each booking attempt on the app, the researchers also took a screenshot on Google Maps with the route automatically suggested by Google. The goal was to record the time and distance recommended by Google, since the app doesn’t display the distance.
If Google Maps’ default route didn’t match the app's, the researchers mimicked Grab’s route on Google Maps and took a second screenshot. This was necessary to get the estimated trip distance, a key piece of data for breaking down the fare.
In addition to the screenshots, all the data was loaded into a spreadsheet.
The researchers conducted a dry-run of the process in January 2024, to detect shortcomings of methodology and improve it before proceeding with the actual data collection in February 2024. After data collection, we conducted several rounds of data cleaning.
Automated collection, from Grab's public API
During the same period as the manual collection, we fetched data from Grab's fare check API for the same 10 routes, but every 15 minutes, to get more granularity.
To query the API, we created a Python script that we improved with the help of ChatGPT. The script uses a system of rotating VPNs implemented using a combination of ProtonVPN, Tunnelblick, and tunblkctl, which allows us to use a different server for each request and thus avoid deadlocks.
Unlike the app, Grab's Farefeed API does not provide the exact fare for a given trip, but an estimated price range, plus estimated waiting time for pick-up and the estimated time to destination. It also returns a field representing the existing surge, whose values can be NONE, LOW_SURGE or HIGH_SURGE.
We fetched data from the API nonstop for an entire week, collecting 672 data points for each of the 10 trips.
Remarkably, on June 20, 2024, shortly after contacting Grab with the results of our investigations, we discovered that the fare check tool and public API were no longer available on the company's website.
How we analyzed the data
After piecing together the data from both sources and checking for consistency, we did a breakdown of the fares using the fare matrix approved by the Land Transportation Franchising and Regulatory Board (LTFRB), the government body that regulates public transportation services.
Here is the formula, as shown in a document from the Philippine Competition Commission (PCC). At the time of the investigation, the basic fare was P45, P15 per kilometer and P2 per minute.

Below is a sample receipt:
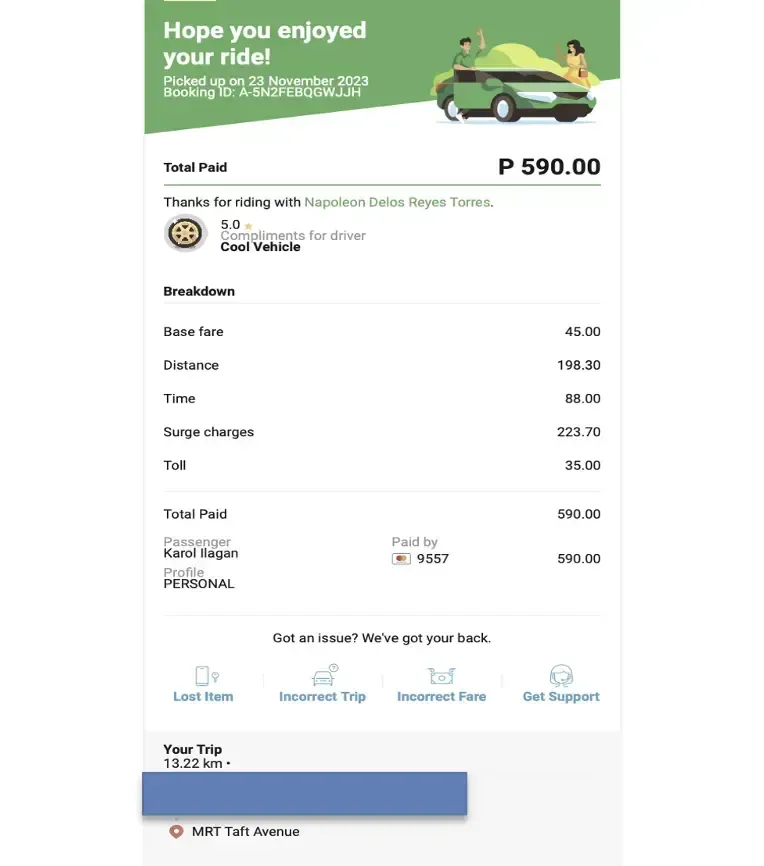
Using the LTFRB fare matrix, we can break down the above fare as follows:
| Fare components | LTFRB approved fare matrix (in PhP) | Fare breakdown using the receipt above (in PhP) |
| Base fare | P45.00 | P45.00 |
| Distance fee | P15.00 | P15 * 13.22 kilometers = P198.30 The app doesn't show the distance upon booking, but it is indicated in the receipt. |
| Duration fee | P2.00 | The app displays a range of the estimated times of arrival to the destination. On the receipt it says P88, so we can estimate that the travel time was 44 minutes. |
| Surge multiplier | Maximum of 2x of the distance and duration fees | Grab charged P223.70 |
Without the surge fee, the trip would have cost only P45 + P198.30 + P88 = P331.30.
Following LTFRB’s fare matrix and Grab’s formula, the maximum surge charge can only reach up to twice the sum of P198.30 and P88 = P286.30 * 2 = P572.60. To calculate the surge multiplier we do as follows:
- Add the costs of distance, duration and surge applied:
P198.30 + P88 + P223.70 = P510 - Divide the result by the sum of the distance and duration costs:
P510 / P286.30 = 1.78 - The surge multiplier (or surge rate) is x1.78. According to Grab, the maximum allowed surge rate is x2.
We used the same formula to get the fare components for each ride we attempted to book. Once all the fares were broken down, we found that a surge fee was always present, meaning that there was always an amount left after subtracting the base fare of P45, the P15 per kilometer and the P2 per minute rates set by the LTFRB.
Obtaining the surge rate allowed us to explore and analyze its relation with other variables, such as the waiting time to start a ride. With the help of statisticians from the School of Statistics at the University of the Philippines Diliman and De La Salle University Manila, we conducted a statistical analysis to scientifically determine whether the waiting time for a ride decreases when the surge fee is higher.
The results didn’t show a significant correlation between the surge rate and waiting times. This contradicts the assumption that a higher rate attracts more cars to the street and lowers waiting times. Certain routes, however, showed a moderated negative and positive correlation between these two variables.
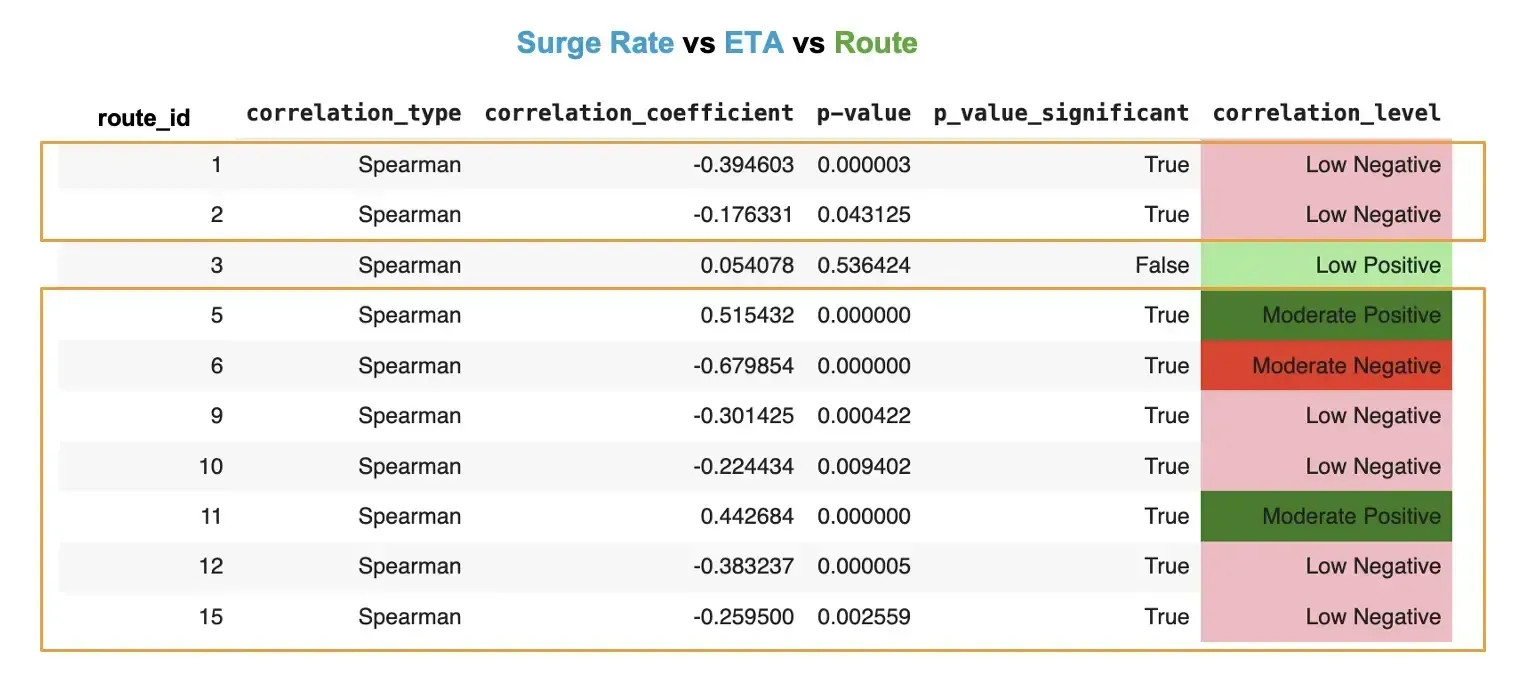
In the table above, surge pricing seemed to work best on route 6 (moderate negative) and then work somewhat on routes 1, 2, 9, 10, 10, 12 and 15 (low negative). Route 6 is in Valenzuela, one of the less busy cities in Metro Manila.
Meanwhile, higher fares didn’t correlate with shorter waiting times on routes 5 and 11. Route 5 pick-up is Makati City, and route 11, Taguig. These are commercial districts of Metro Manila.
Other sources to report the story
In addition to quantitative sources, we drew on several qualitative sources:
- To understand the impact of the algorithm, we learned from the experiences of at least a dozen commuters and 50 drivers. We contacted people who used GrabCar frequently and interviewed drivers and passengers from several routes where they used to rest, such as Diokno Boulevard and Macapagal Avenue in Pasay City. Some of the interviewees requested anonymity for fear of retaliation.
- To help inform the data collection process, we read multiple transportation studies on surge pricing.
- We interviewed representatives from organizations monitoring ride-hailing companies and digital labor.
- We tried to request data and interviews from the LTFRB, the Department of Trade and Industry’s Consumer Protection Group, the Department of Information and Communication Technology (DICT), and the PCC. To date, only the DICT and the PCC have responded. These interview requests focused on the government's role as a regulator, what the law, policy or rules and regulations do or do not say about algorithms, and Grab's market dominance when it acquired Uber's operations in the Philippines.
Limitations of our methodology and more things to explore
The data we obtained shows some aspects of how Grab's algorithm works, but we are aware that our methodology has certain limitations and that due to lack of time and resources there are some issues that we weren’t able to delve into further.
- Our data collection lasted one week, but for a more comprehensive analysis it would be ideal to collect data for a longer period.
- We didn’t perform any quantitative data collection from the drivers' side. Although, unlike users, drivers cannot "choose" the rides, performing systematic data collection from their perspective could help illuminate other aspects of Grab’s pricing algorithm.
- In our methodology, we didn’t consider the general direction of travel throughout the day. Urban mobility has very clear patterns: During the morning people tend to move toward commercial areas while in the evening they return to residential areas. We considered the 10 routes always in the same direction; collecting pricing data for each route in both directions would allow a better understanding of the changes in supply and demand throughout the day.
- We left out from our research things such as traffic and weather. Those variables could be obtained from other sources (Google API, TomTom, etc.) to correlate with Grab data and try to understand how they impact the prices.
- An interesting line of research that we couldn’t test on this occasion is whether Grab shows different prices to users of different gender, age group, member seniority in the app, socioeconomic conditions, etc.
Lessons learned on how to report on algorithms
These are some of the lessons we learned during this process. We hope they can be useful to other journalists interested in the field of algorithmic accountability:
- Although we cannot get into the black box of an algorithm, we can obtain very relevant information if we work on its inputs and outputs. The key is to design a methodology for systematic data collection.
- When designing a manual data collection experiment, it’s important to test it before conducting the actual collection, especially if several people are involved in the process. The pre-meetings and the dry run allowed us to establish a clear and consistent baseline to work with the data, identify weaknesses, and improve it.
- You don’t need advanced coding skills to audit the outputs of an algorithm: a well-done manual data collection can be enough. The data collected manually by our team was always within the price range returned by the API, which demonstrates the consistency of both data sources.
- If you plan to manually save several data from a platform or an app at an exact moment in time, a screenshot is probably your best friend. It's the fastest way, can be used as proof, and you can move the data to a spreadsheet later, when time is not pressing, to perform the data analysis.
- When auditing an algorithm, think of other data sources that can complement the missing information. In our case, for example, Google Maps allowed us to establish the estimated distance of the trips, a data that neither the API nor the Grab app provided.
- If you have a lot of data and variables to analyze and the relation between them is complex, the help of a statistician will allow you to identify relevant patterns but also to avoid making hasty assumptions. It also strengthens your conclusions.
- When researching a technical topic, such as an algorithm that calculates fares, it’s key to include the human perspective as well. Testimonials from users and drivers allowed us to show how people are impacted by these systems and the true scale of the problem.

